


Ceph 是一个开源的分布式存储系统,广泛应用于大规模数据存储和处理场景。为了确保 Ceph 集群的稳定运行,运维人员需要掌握一些基本的维护命令。本文将详细介绍一些常用的 Ceph 维护命令,并提供相应的示例。
- 查看集群状态
命令:ceph status
描述:该命令用于查看 Ceph 集群的整体状态,包括集群的健康状况、OSD 状态、PG 状态等。
示例:
$ ceph status
cluster:
id: a7f64266-0894-4f1e-a635-d0aeaca0e993
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 3h)
mgr: a(active, since 3h)
osd: 3 osds: 3 up (since 3h), 3 in (since 3h)
data:
pools: 1 pools, 100 pgs
objects: 100 objects, 1.0 GiB
usage: 3.0 GiB used, 27 GiB / 30 GiB avail
pgs: 100 active+clean详解:
cluster:显示集群的唯一标识符和健康状态。
services:列出集群中的服务,如 Monitor (mon)、Manager (mgr) 和 OSD (osd)。
data:显示数据池、对象、存储使用情况和 PG 状态。
- 查看 OSD 状态
命令:ceph osd status
描述:该命令用于查看集群中所有 OSD 的状态,包括 OSD 的 ID、状态、权重等。
示例:
$ ceph osd status
+----+------------+-------+-------+--------+---------+--------+---------+-----------+
| id | host | used | avail | wr ops | wr data | rd ops | rd data | state |
+----+------------+-------+-------+--------+---------+--------+---------+-----------+
| 0 | node1 | 1.0G | 9.0G | 0 | 0 | 0 | 0 | exists,up |
| 1 | node2 | 1.0G | 9.0G | 0 | 0 | 0 | 0 | exists,up |
| 2 | node3 | 1.0G | 9.0G | 0 | 0 | 0 | 0 | exists,up |
+----+------------+-------+-------+--------+---------+--------+---------+-----------+详解:
id:OSD 的唯一标识符。
host:OSD 所在的节点。
used:OSD 已使用的存储空间。
avail:OSD 可用的存储空间。
state:OSD 的状态,如 exists,up 表示 OSD 存在且正在运行。
- 查看 PG 状态
命令:ceph pg dump
描述:该命令用于查看集群中所有 Placement Group (PG) 的状态,包括 PG 的 ID、状态、OSD 分布等。
示例:
$ ceph pg dump
dumped all
version 101
stamp 2023-10-01 12:34:56.789
last_osdmap_epoch 100
last_pg_scan 100
PG_STAT OBJECTS MISSING_ON_PRIMARY DEGRADED MISPLACED UNFOUND BYTES LOG DISK_LOG STATE STATE_STAMP VERSION REPORTED UP UP_PRIMARY ACTING ACTING_PRIMARY LAST_SCRUB SCRUB_STAMP LAST_DEEP_SCRUB DEEP_SCRUB_STAMP
1.0 100 0 0 0 0 1024M 32 32 active+clean 2023-10-01 12:34:56.789 101:100 101:100 [0,1,2] 0 [0,1,2] 0 2023-09-30 12:34:56.789 2023-09-30 12:34:56.789 2023-09-30 12:34:56.789详解:
PG_STAT:PG 的状态信息。
OBJECTS:PG 中的对象数量。
STATE:PG 的状态,如 active+clean 表示 PG 处于活动且干净的状态。
UP:当前负责该 PG 的 OSD 列表。
ACTING:实际负责该 PG 的 OSD 列表。
- 查看 Monitor 状态
命令:ceph mon stat
描述:该命令用于查看集群中所有 Monitor 的状态,包括 Monitor 的数量和仲裁状态。
示例:
$ ceph mon stat
e3: 3 mons at {a=192.168.1.1:6789/0,b=192.168.1.2:6789/0,c=192.168.1.3:6789/0}, election epoch 10, quorum 0,1,2 a,b,c详解:
e3:Monitor 的选举纪元。
3 mons:集群中有 3 个 Monitor。
quorum 0,1,2:当前的仲裁成员。
- 查看 Manager 状态
命令:ceph mgr stat
描述:该命令用于查看集群中所有 Manager 的状态,包括 Manager 的数量和活动状态。
示例:
$ ceph mgr stat
{ "epoch": 100, "available": true, "num_standbys": 1, "modules": ["dashboard", "restful"], "services": {"dashboard": "https://node1:8443/"} }详解:
epoch:Manager 的纪元。
available:Manager 是否可用。
num_standbys:备用 Manager 的数量。
modules:已启用的 Manager 模块。
services:Manager 提供的服务,如 Dashboard。
- 查看集群使用情况
命令:ceph df
描述:该命令用于查看集群的存储使用情况,包括总容量、已使用容量和可用容量。
示例:
$ ceph df
GLOBAL:
SIZE AVAIL RAW USED %RAW USED
30 GiB 27 GiB 3.0 GiB 10.00
POOLS:
NAME ID USED %USED MAX AVAIL OBJECTS
pool1 1 1.0 GiB 3.33% 9.0 GiB 100详解:
GLOBAL:集群的整体存储使用情况。
POOLS:各个存储池的使用情况。
USED:已使用的存储空间。
%USED:已使用的存储空间占总容量的百分比。
- 查看集群日志
命令:ceph log last
描述:该命令用于查看集群的最新日志,帮助排查问题。
示例:
$ ceph log last
2023-10-01T12:34:56.789 [INF] osd.0: OSD started
2023-10-01T12:34:56.789 [INF] osd.1: OSD started
2023-10-01T12:34:56.789 [INF] osd.2: OSD started详解:
日志按时间顺序列出,最新的日志在最前面。
- 查看集群配置
命令:ceph config show
描述:该命令用于查看集群的配置信息,包括各种参数的当前值。
示例:
$ ceph config show osd.0
{
"osd_data": "/var/lib/ceph/osd/ceph-0",
"osd_journal": "/var/lib/ceph/osd/ceph-0/journal",
"osd_max_backfills": "10",
"osd_recovery_max_active": "5",
"osd_recovery_op_priority": "10"
}详解:
显示指定 OSD 的配置信息。
- 查看集群性能
命令:ceph perf dump
描述:该命令用于查看集群的性能指标,包括读写操作的延迟、吞吐量等。
示例:
$ ceph perf dump
{
"osd": {
"0": {
"op_w": 0,
"op_r": 0,
"op_rw": 0,
"op_w_latency": 0.0,
"op_r_latency": 0.0,
"op_rw_latency": 0.0
},
"1": {
"op_w": 0,
"op_r": 0,
"op_rw": 0,
"op_w_latency": 0.0,
"op_r_latency": 0.0,
"op_rw_latency": 0.0
},
"2": {
"op_w": 0,
"op_r": 0,
"op_rw": 0,
"op_w_latency": 0.0,
"op_r_latency": 0.0,
"op_rw_latency": 0.0
}
}
}详解:
op_w:写操作的数量。
op_r:读操作的数量。
op_w_latency:写操作的平均延迟。
op_r_latency:读操作的平均延迟。
- 查看集群告警
命令:ceph health detail
描述:该命令用于查看集群的健康状态,并提供详细的告警信息。
示例:
$ ceph health detail
HEALTH_WARN 1 pgs degraded; 1 pgs stuck unclean; 1 pgs undersized
pg 1.0 is stuck unclean for 10m, current state active+undersized+degraded, last acting [0,1]详解:
HEALTH_WARN:集群处于警告状态。
pg 1.0:具体的 PG 告警信息。
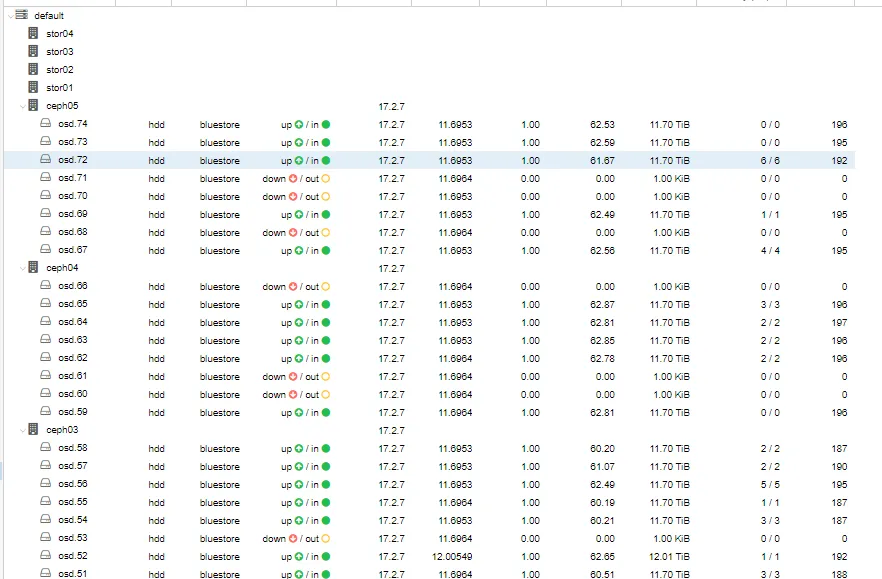
11.查看 OSD 使用情况
命令:ceph osd df tree
描述:该命令用于查看 Ceph 集群中各个 OSD(Object Storage Daemon)的使用情况,并以树形结构展示。通过该命令,可以直观地了解每个 OSD 的存储使用率、剩余空间等信息。
示例:
ceph osd df tree
ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS TYPE NAME
-1 3.00000 300G 100G 100G 0B 100G 200G 33.33 1.00 - root default
-3 1.00000 100G 33G 33G 0B 33G 67G 33.00 1.00 - host node1
0 hdd 1.00000 100G 33G 33G 0B 33G 67G 33.00 1.00 222 osd.0
-5 1.00000 100G 33G 33G 0B 33G 67G 33.00 1.00 - host node2
1 hdd 1.00000 100G 33G 33G 0B 33G 67G 33.00 1.00 222 osd.1
-7 1.00000 100G 33G 33G 0B 33G 67G 33.00 1.00 - host node3
2 hdd 1.00000 100G 33G 33G 0B 33G 67G 33.00 1.00 222 osd.2详解:
ID:OSD 的唯一标识符。
CLASS:OSD 的存储类型(如 HDD、SSD)。
WEIGHT:OSD 的权重。
SIZE:OSD 的总容量。
RAW USE:OSD 的实际使用量。
AVAIL:OSD 的可用空间。
%USE:OSD 的使用率。
PGS:分配给该 OSD 的 Placement Groups 数量。
通过 ceph osd df tree 命令,运维人员可以快速了解集群中各个 OSD 的存储使用情况,及时发现并处理存储空间不足的问题。

评论 (0)